很多团队在模型上线后,才开始补监控与告警,最终陷入“出问题—加规则—再出问题”的被动循环。成熟的 MLOps 监控体系应从一开始就和工程实践一体化:在数据、模型、服务三个层面明确指标与阈值,定义告警升级与回滚路径,形成可追溯的证据链。本文从实践出发,总结我们在客户项目中的通用做法,帮助你用最小代价建立可靠的监控底座。
一、数据层:分布、质量与合规
数据漂移是模型退化的根因。离线阶段可建立基线分布(特征均值/方差、类别占比、Top-K 词频),上线后持续采样生产数据并进行统计对比,使用 PSI、KL 散度或 KS 检验评估偏移程度。对文本任务,关注语言、领域术语与长度分布;对视觉任务,关注分辨率、光照、角度等元数据。
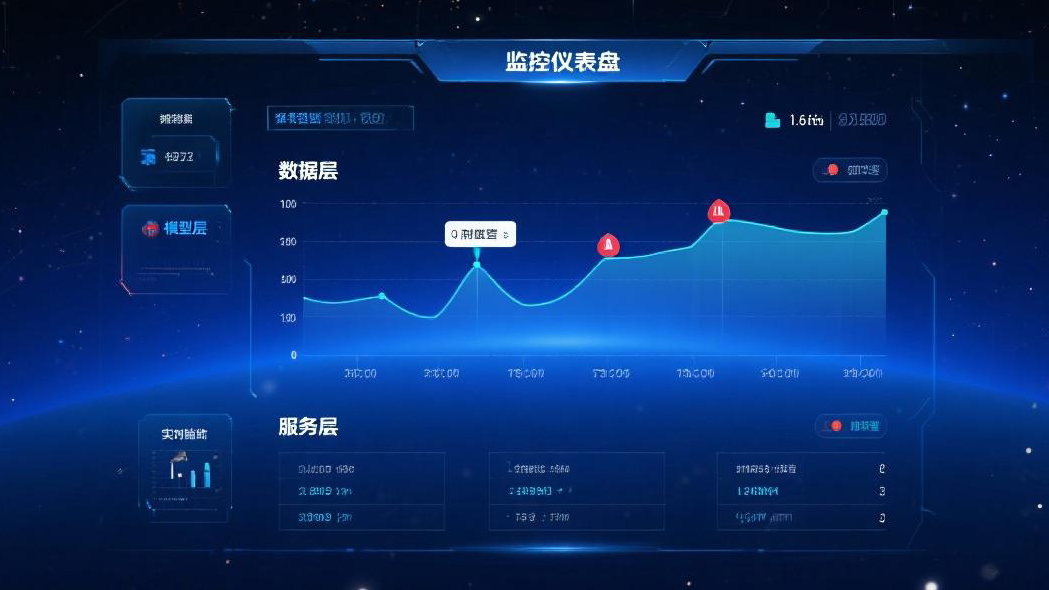
质量方面,构建数据质量规则库:缺失率、重复率、异常值、时间戳逆序、标签一致性。每条规则都有严重度和处理策略(丢弃、修正、隔离),并产出每批次的质检报告。合规方面,建立 PII 检测与脱敏流水线,所有数据入库前走合规通道,留存审计记录。
二、模型层:性能、稳定与可解释
离线评估不仅要看单一指标,更要看稳定区间和置信区间。在推理阶段,收集实时指标:置信度分布、Top-K 置信度差、拒答率/降级率、温度与采样参数落点。对于分类/排序类任务,记录混淆矩阵随时间变化;对于生成类任务,记录自评打分与参考打分的偏移。可解释性方面,保存代表性样本的注意力/显著性信息,辅助问题复盘。
三、服务层:SLO、容量与成本
服务层的监控以用户体验为核心。关键指标包含:可用性(Availability)、错误率、首字延迟/总时延(P50/P95/P99)、队列长度、CPU/GPU/内存利用率、连接数与池化命中率。容量管理采用负载曲线+弹性伸缩策略,预设高峰与容灾演练。成本监控需要到“每条请求”的粒度,记录模型调用时长、Token 数、外部 API 费用,并按组织/项目/环境打标签汇总。
四、告警与处置:分层与演练
告警要分层:P1 影响核心流程且无替代路径,需自动触发降级/回滚;P2 影响部分用户或有替代路径;P3 对体验影响可接受。每条告警携带定位线索(近 5 分钟参数、依赖可用性、最近版本变更),并绑定处置手册。每季度进行故障演练,验证回滚与应急通道可用。
五、灰度发布与版本治理
任何影响输出质量的变更都应通过灰度:从影子流量开始,逐步扩大比例。为每个模型/提示词/特征工程建立版本号,与实验平台打通,做到“问题可回放、结果可复现”。回滚策略应覆盖模型版本、参数、提示词与依赖外部服务的切换。
六、跨团队协作:责任到人
MLOps 的成败在协作。建议明确 RACI:数据团队对数据质量负责,算法团队对模型质量与退化响应负责,平台团队对服务 SLO 与成本负责,业务团队对指标定义与验收负责。通过统一的看板和周会机制,把监控与动作闭环到人。
七、实践清单
最后给出一份最小可行清单: 1)建立离线评测集与基线分布;2)接入数据质量与 PII 检测;3)上线实时性能与成本指标;4)配置分层告警与处置手册;5)落地灰度发布与回滚;6)打通版本与实验平台;7)建立跨团队例行复盘。按此路径推进,你将获得一个稳定、经济、可审计的机器学习生产系统。
如需在你的组织中落地上述能力,欢迎与我们联系。SFK 提供监控系统搭建、指标体系设计到应急演练的一体化服务。